Alexander Steshenko | On Software Engineering
Phystrix: latency and fault tolerance library for PHP
On every major project I’ve worked on we had a situation when a database query or an HTTP call to a remote service would start timing out and failing. At times that would cause the entire aplication to degrade or go down completely. We would try to fix every case, often in an urgent manner, or manually disable the piece causing trouble so we had at least the rest of the application running. Eventually we’d introduce timeouts for critical pieces and wrap parts of code into try/catch blocks.
The truth is: in complex distributed systems a failure is inevitable. Please meet Phystrix: a PHP library by oDesk we recently open-sourced. It helps solving the problem in a uniform clear way.
Example
Let’s say you have a SQL query to get top commenter on your web site for the last week
$startDate = strtotime("-1 week");
$sql = "
SELECT
U.DisplayName,
COUNT(C.ID) AS CommentCount
FROM
Users AS U
INNER JOIN Comments AS C ON U.ID = C.UserID
GROUP BY
U.DisplayName
WHERE C.time > ?
ORDER BY
COUNT(C.ID) DESC
LIMIT 1;
";
$topCommenterName = $db->fetchOne($sql, $startDate); // passing start date as a parameterYou may be invoking it directly or your ORM may be doing this for you.
One day you notice your app has slowed down and getting worse with time, your clients are complaining. Having stress and working over time, you finally find out that the culprit is this query. It serves to display some piece of information on every page load. Until you have it figured it out, you disable the widget, letting the rest of the application run. Things are back to normal for a while.
It doesn’t even matter what exactly was wrong with the query. You may have misconfigured some RDBMS indexes, or your initial analysis of how the data was going to be used was wrong. It doesn’t have to be a SQL query either, may as well be an HTTP call to a backend or to something like Google API.
With Phystrix, you wrap your SQL in a command (see CommandPattern):
use Odesk\Phystrix\AbstractCommand;
class GetTopCommenterNameCmd extends AbstractCommand
{
protected $startDate;
public function __construct($startDate)
{
$this->startDate = $startDate;
}
protected function run()
{
// obtaining the "db" dependency from Phystrix service locator
$db = $this->serviceLocator->get('db');
$sql = "
SELECT
U.DisplayName,
COUNT(C.ID) AS CommentCount
FROM
Users AS U
INNER JOIN Comments AS C ON U.ID = C.UserID
GROUP BY
U.DisplayName
WHERE C.time > ?
ORDER BY
COUNT(C.ID) DESC
LIMIT 1;
";
return $db->fetchOne($sql, $this->_startDate);
}
protected function getFallback()
{
return "temporary not available";
}
}Then, whenever you need to execute it, you instantiate your command and call the execute() method:
$getTopCommenterNameCmd =
$phystrixFactory->getCommand('GetTopCommenterName', strtotime('-1 week'));
$topCommenterName = $getTopCommenterNameCmd->execute();Here the command is instantiated via the Phystrix command factory, which makes sure all required dependencies are injected. You could instantiate the command with the new keyword, too. You would need to incorporate some static initialization code into your commands for that:
$getTopCommenterNameCmd = new GetTopCommenterName(strtotime('-1 week'));
$topCommenterName = $getTopCommenterNameCmd->execute();Now, with the command pattern used to isolate the SQL query, Phystrix will count all successful and failed requests. If within a specific timeframe the query times out more than it’s allowed, Phystrix will block the query and return getFallback() function result instead. For a while, Phystrix will not attempt to execute the query again! Letting the rest of your application function as it should and relieving the database engine.
In case it was a temporary outage, Phystrix will be trying to execute the query every once in a while. One single attempt to see if this point of access to the database is back up. If it is - Phystrix unblocks the command and starts gathering success/failure statistics again.
Phystrix configuration
How Phystrix behaves is fully configuration-driven. Following examples on the official GitHub page, you can instantiate the command factory by providing a configuration file:
array( // Default configuration
'fallback' => array(
// Whether getFallback should be used (throws an exception if it's false)
'enabled' => false,
),
'circuitBreaker' => array(
'enabled' => true,
'forceOpen' => false
// How many failures within the statistical window is required for the command to be "blocked"
'errorThresholdPercentage' => 50,
// The number of executions within the window before we can block the command
'requestVolumeThreshold' => 10,
// How often to ping the remote system, after the command is blocked
'sleepWindowInMilliseconds' => 5000,
),
'metrics' => array(
'healthSnapshotIntervalInMilliseconds' => 1000,
'rollingStatisticalWindowBuckets' => 10,
// Statistical window size. 10 seconds here
'rollingStatisticalWindowInMilliseconds' => 10000,
),
'requestCache' => array(
'enabled' => false,
),
'requestLog' => array(
'enabled' => false,
),
),
'GetTopCommenterName' => array( // Command specific configuration
'fallback' => array(
'enabled' => true
)
)
);“Circuit Breaker” is the feature responsible for blocking any given command execution. For instance, if you want to disable a command unconditionally - you can do so by setting “forceOpen” to true.
You can also pass any custom configuration parameters, like a SQL timeout specific to a particular command:
'GetTopCommenterName' => array( // Command specific configuration
'sql' => array(
'timeout' => 30
)
)you can then obtain this configuration in your command as follows:
protected function run()
{
// obtaining the "db" dependency from Phystrix service locator
$db = $this->serviceLocator->get('db');
$db->query('SET TIMEOUT ?', $this->config->get('sql')->get('timeout'));
// ...
}You can also define configuration for a particular context:
// e.g. on a page, where getting the top commenter is more critical we set a higher timeout:
$getTopCommenterNameCmd->setConfig(new Config(array('sql' => array('timeout' => 60))));
$topCommenterName = $getTopCommenterNameCmd->execute();Additional features
Phystrix has a similar feature set as Hystrix - the library for Java by Netflix. Request cache and request log, custom service locator, flexible configuration - all these make Phystrix usage convenient. Read more about them on the official GitHub Page.
It’s also possible to use the awesome Hystrix monitoring tool with Phystrix:
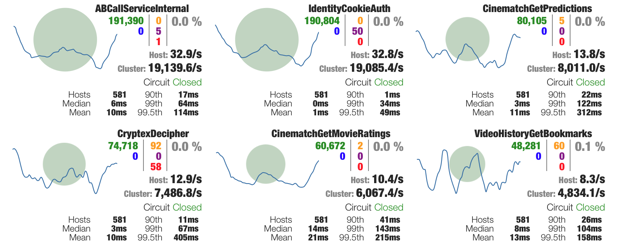
See Phystrix Dashboard for that.
Conclusion
After using Phystrix in production environment for a while I can see that every project I worked on in the past would benefit from it. For enterprise, high-load, complex distributed systems with diverse data source - a tool like Phystrix is simply a must.